- 프로젝트 DB 설계에 관하여 2023.04.03
- 30. ROW_NUMBER, 시퀀스(SEQUENCE) 2022.03.29
- 29. 중첩 그룹함수 / 분석함수 2022.03.12
- 28. HAVING 2022.03.12
- 27. CUBE 2022.03.12
- 26. ROLLUP, GROUPING 2022.03.12
프로젝트 링크 : https://github.com/yesaroun/MoneyLog
GitHub - yesaroun/MoneyLog
Contribute to yesaroun/MoneyLog development by creating an account on GitHub.
github.com
1년 전에 spring 기반의 가계부를 구현하는 프로젝트를 진행했었습니다.
이 프로젝트를 통해서 DB 설계와 정규화를 직접 구현해 볼 수 있었습니다.

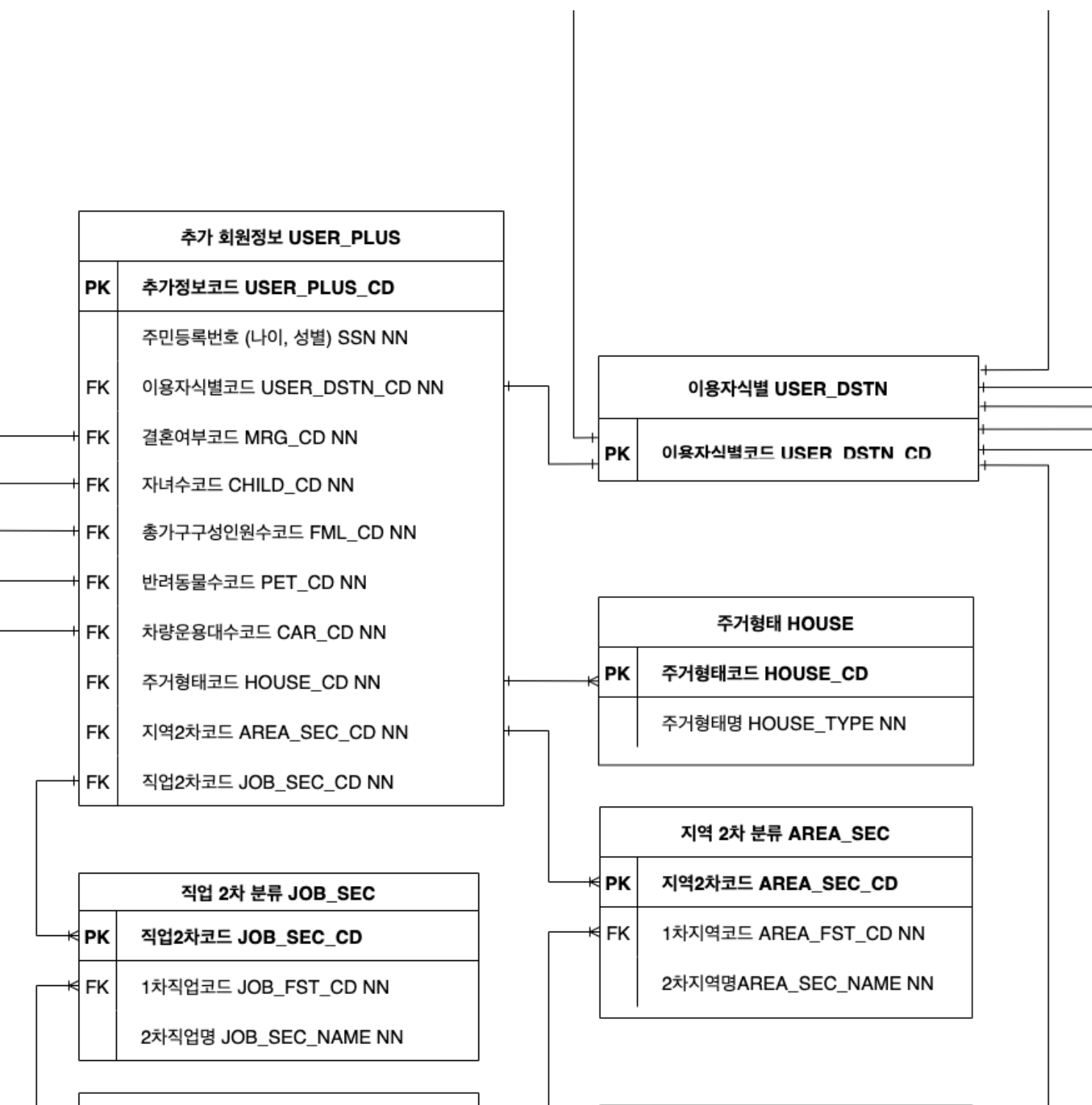
전체적인 ERD 구조는 위와 같습니다.
하나씩 구체적으로 살펴보면서 설계한 이유를 적어보겠습니다.
이용자 식별 코드

'이용자식별' 테이블을 만들었습니다.
이렇게 설계한 이유는 후술할 탈퇴 계정과 추가회원정보와 연관이 깊습니다.
저희 서비스는 회원의 정보를 활용한 통계 자료가 매우 중요했습니다. 그러기에 회원이 탈퇴했을 경우 관련 데이터를 함께 탈퇴 테이블로 옮긴다면, 서비스에 활용될 데이터 또한 사라져 버리는 문제가 발생합니다.
그래서 생각해낸 방법이 임의의 코드로 만들어진 이용자 식별 코드를 따로 분리해 '회원정보'테이블과 '추가회원정보'테이블에서 외래키로 받는 방법이었습니다.
이 경우 아래에 있는 '그림1)'처럼 탈퇴에 사용될 회원 정보와 '그림2)'의 통계 자료로 활용할 추가적인 회원 정보를 분리할 수 있었습니다.
이러면 회원이 탈퇴 했을 경우 '회원정보'테이블에 있는 회원 정보만 '탈퇴계정백업'테이블로 보내고, 나머지 정보는 그대로 활용할 수 있었습니다.

탈퇴 계정
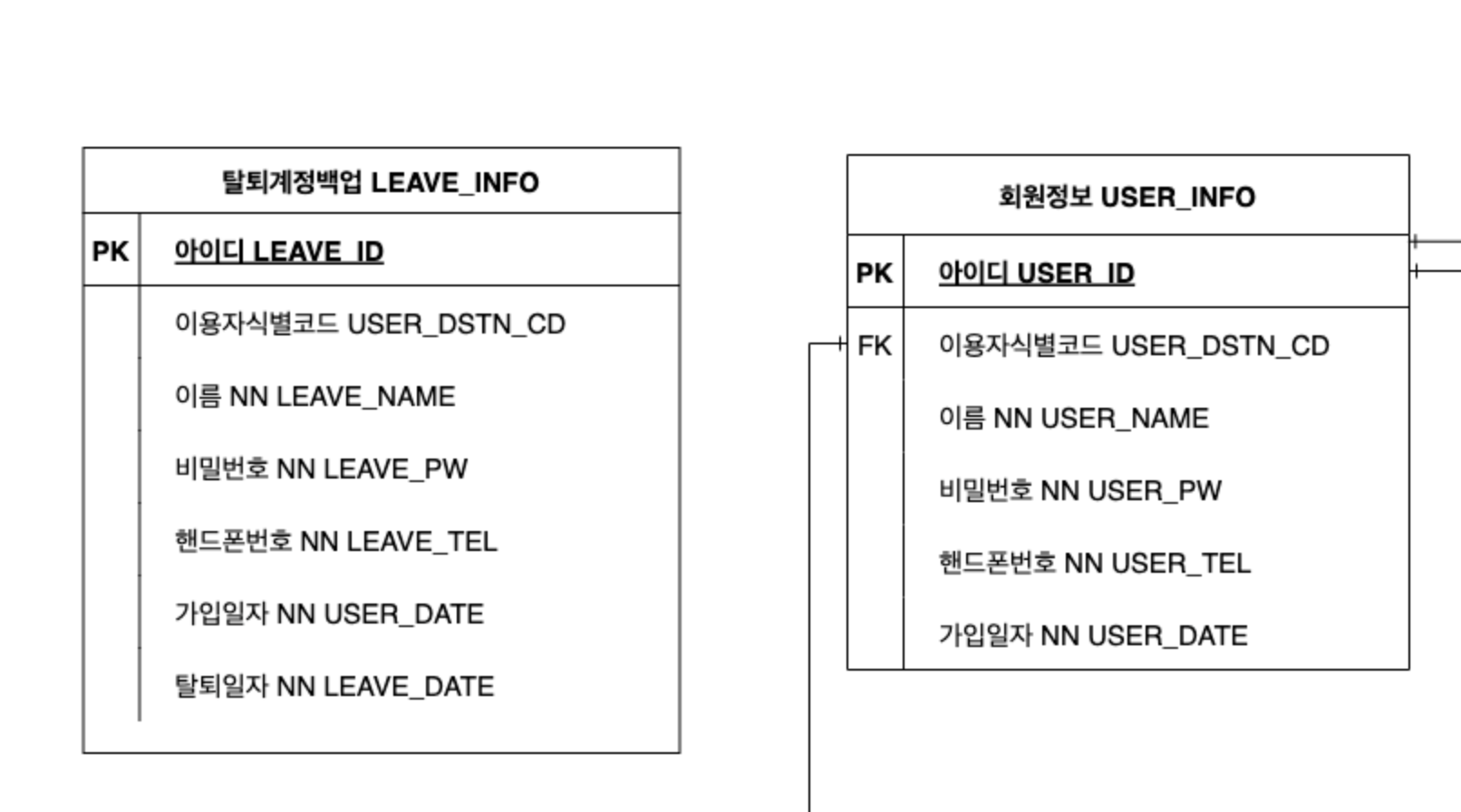
회원이 탈퇴를 했을 경우 바로 회원 정보를 테이블에서 지우는게 아닌 '탈퇴계정백업'테이블에 일정 기간 저장하는 방식입니다.
추가회원정보
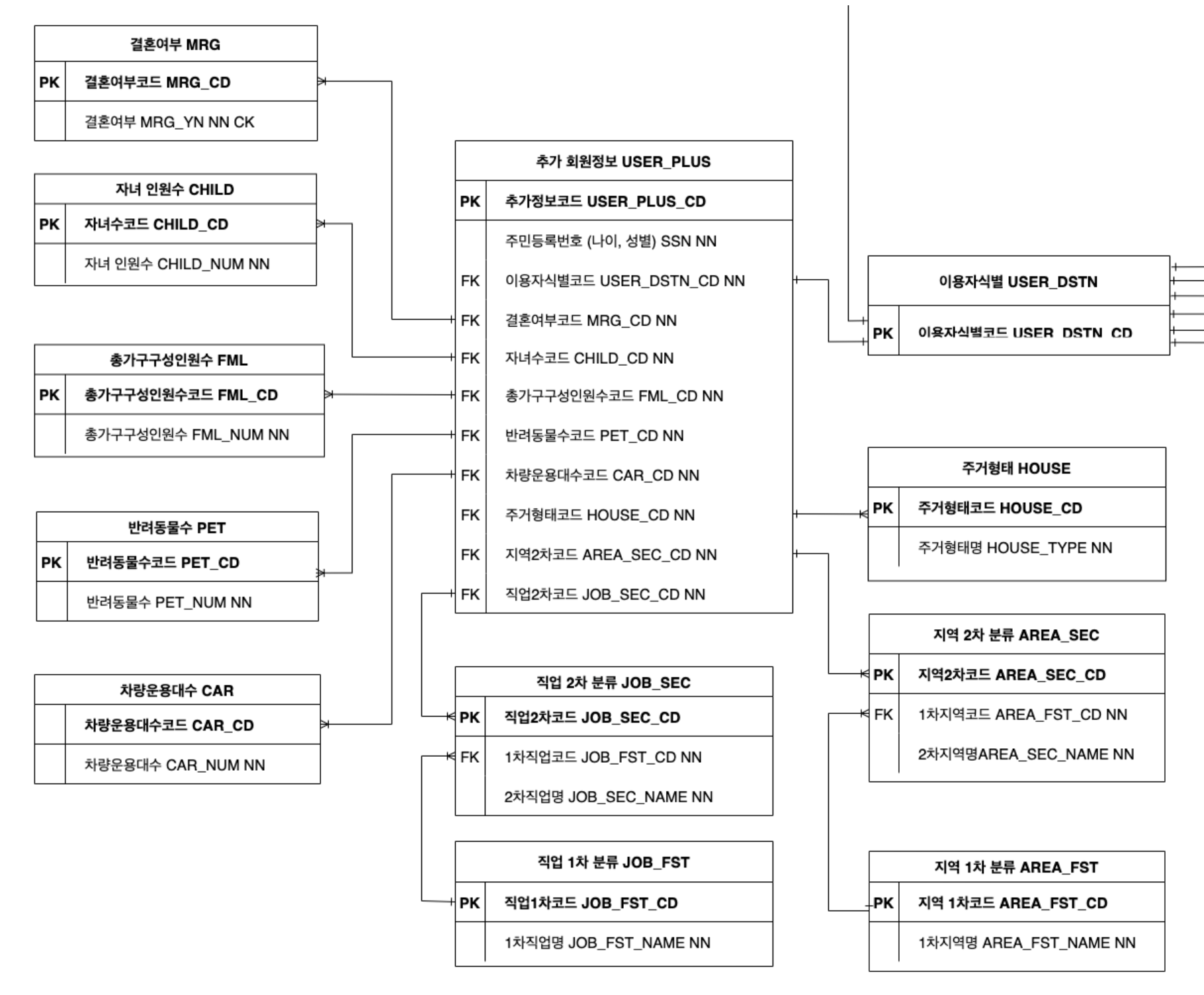
추가 회원 정보를 단순하게 '추가회원정보'테이블에 직접 값을 입력하는 방식이 아닌 정규화를 통해서 분해했습니다.
예를 들어 반려동물수를 살펴보면,
'반려동물수' 테이블을 따로 만들어서 여기에는
| 반려동물수코드(PK) | 반려동물수 |
| 1 | 0마리 |
| 2 | 1마리 |
| 3 | 2마리 |
| ... | ... |
이런 값이 들어가고 '추가회원정보'테이블에는 해당하는 외래키를 가져다가 사용하는 방식입니다.
'SQL > Oracle' 카테고리의 다른 글
| 30. ROW_NUMBER, 시퀀스(SEQUENCE) (0) | 2022.03.29 |
|---|---|
| 29. 중첩 그룹함수 / 분석함수 (0) | 2022.03.12 |
| 28. HAVING (0) | 2022.03.12 |
| 27. CUBE (0) | 2022.03.12 |
| 26. ROLLUP, GROUPING (0) | 2022.03.12 |
ROW_NUMBER
PARTITION 내에서 ORDER BY절에 의해 정렬된 순서를 기준으로 고유한 값을 반환
e.g.
SELECT ROW_NUMBER() OVER(ORDER BY SAL DESC) "테스트"
, ENAME "사원명", SAL "급여", HIREDATE "입사일"
FROM EMP;
--==>>
/*
1 KING 5000 1981-11-17
2 FORD 3000 1981-12-03
3 SCOTT 3000 1987-07-13
4 JONES 2975 1981-04-02
5 BLAKE 2850 1981-05-01
6 CLARK 2450 1981-06-09
7 ALLEN 1600 1981-02-20
8 TURNER 1500 1981-09-08
9 MILLER 1300 1982-01-23
10 WARD 1250 1981-02-22
11 MARTIN 1250 1981-09-28
12 ADAMS 1100 1987-07-13
13 JAMES 950 1981-12-03
14 SMITH 800 1980-12-17
*/
SELECT ROW_NUMBER() OVER(ORDER BY SAL DESC) "테스트"
, ENAME "사원명", SAL "급여", HIREDATE "입사일"
FROM EMP
ORDER BY ENAME;
--==>>
/*
12 ADAMS 1100 1987-07-13
7 ALLEN 1600 1981-02-20
5 BLAKE 2850 1981-05-01
6 CLARK 2450 1981-06-09
2 FORD 3000 1981-12-03
13 JAMES 950 1981-12-03
4 JONES 2975 1981-04-02
1 KING 5000 1981-11-17
11 MARTIN 1250 1981-09-28
9 MILLER 1300 1982-01-23
3 SCOTT 3000 1987-07-13
14 SMITH 800 1980-12-17
8 TURNER 1500 1981-09-08
10 WARD 1250 1981-02-22
*/
-- 번호는 급여를 기준으로 부여했지만 정렬은 이름 순
문자 기준 정렬도 가능
SELECT ROW_NUMBER() OVER(ORDER BY ENAME) "테스트"
, ENAME "사원명", SAL "급여", HIREDATE "입사일"
FROM EMP
ORDER BY ENAME;
--==>>
/*
1 ADAMS 1100 1987-07-13
2 ALLEN 1600 1981-02-20
3 BLAKE 2850 1981-05-01
4 CLARK 2450 1981-06-09
5 FORD 3000 1981-12-03
6 JAMES 950 1981-12-03
7 JONES 2975 1981-04-02
8 KING 5000 1981-11-17
9 MARTIN 1250 1981-09-28
10 MILLER 1300 1982-01-23
11 SCOTT 3000 1987-07-13
12 SMITH 800 1980-12-17
13 TURNER 1500 1981-09-08
14 WARD 1250 1981-02-22
*/
부서 번호가 20번인 사원에 번호 부여
SELECT ROW_NUMBER() OVER(ORDER BY ENAME) "테스트"
, ENAME "사원명", SAL "급여", HIREDATE "입사일"
FROM EMP
WHERE DEPTNO = 20
ORDER BY ENAME;
--==>>
/*
1 ADAMS 1100 1987-07-13
2 FORD 3000 1981-12-03
3 JONES 2975 1981-04-02
4 SCOTT 3000 1987-07-13
5 SMITH 800 1980-12-17
*/
※ 게시판의 게시물 번호를 SEQUENCE(오라클) 나 IDENTITY(MSSQL)를 사용하게 되면 게시물을 삭제했을 경우, 삭제한 게시물의 자리에 다음 번호를 가진 게시물이 등록되는 상황이 발생 이는 보안성 측면이나 미관성 바람직하지 않기에 ROW_NUMBER()의 사용을 고려해 볼 수 있다. 관리의 목적으로 사용할 때에는 SEQUENCE 나 IDENTITY를 사용하지만 단순히 게시물을 목록화하여 사용자에게 리스트 형식으로 보여줄 때에는 사용하지 않는 것이 바람직
시퀀스 생성
CREATE SEQUENCE SEQ_BOARD -- 기본적인 시퀀스 생성 구문
START WITH 1 -- 시작값
INCREMENT BY 1 -- 증가값
NOMAXVALUE -- 최대값
NOCACHE; -- 캐시사용여부
시퀀스 삭제
DROP SEQUENCE SEQ_BOARD;
테이블에 데이터 입력하면서 시퀀스 사용하기
INSERT INTO TBL_BOARD VALUES
(SEQ_BOARD.NEXTVAL, '풀숲', '전 풀숲에 있어요')

부족하거나 잘못된 내용이 있을 경우 댓글 달아주시면 감사하겠습니다.
이 글에 부족한 부분이 존재할 경우 추후에 수정될 수 있습니다.
'SQL > Oracle' 카테고리의 다른 글
| 프로젝트 DB 설계에 관하여 (0) | 2023.04.03 |
|---|---|
| 29. 중첩 그룹함수 / 분석함수 (0) | 2022.03.12 |
| 28. HAVING (0) | 2022.03.12 |
| 27. CUBE (0) | 2022.03.12 |
| 26. ROLLUP, GROUPING (0) | 2022.03.12 |
그룹 함수는 2LEVEL 까지 중첩해서 사용할 수 있다. MSSQL은 이마저도 불가능하다.
그룹 함수를 중첩
SELECT MAX(SUM(SAL))
FROM EMP
GROUP BY DEPTNO;
--==>> 10875
RANK(), DENSE_RANK()
→ ORACLE 9i 부터 적용, MSSQL 2005부터 적용
하위 버전에서는 RANK() 나 DENSE_RANK()를 사용할 수 없다
만약 이전 버전에서 순위를 구하려면 다음과 같이 해야 한다.
만약 급여 순위를 구하고자 한다면 해당 사원의 급여보다 더 큰 값이 몇 개인지를 확인한 후 확인한 값에 +1을 추가 연산해 주면 그 값이 곧 해당 사원의 급여 등수가 된다.
SELECT *
FROM EMP;
-- 급여 확인
-- SMITH 급여 등수 확인
SELECT COUNT(*) + 1
FROM EMP
WHERE SAL > 800; -- SMITH의 급여
--==>> 14 -- SMITH의 급여 등수
-- ALLEN 급여 등수 확인
SELECT COUNT(*) + 1
FROM EMP
WHERE SAL > 1600; -- ALLEN의 급여
--==>> 7 -- ALLEN의 급여 등수
서브 상관 쿼리(상관 서브 쿼리)
메인 쿼리가 있는데 테이블의 컬럼이 서브 쿼리의 조건절(WHERE절, HAVING절) 에 사용되는 경우 이 쿼리문을 서브 상관 쿼리(상관 서브 쿼리)라고 부른다.
SELECT ENAME "사원명", SAL "급여"
, (SELECT COUNT(*) + 1
FROM EMP
WHERE SAL > E.SAL) "급여등수"
FROM EMP E;
*--==>>
/**
SMITH 800 14
ALLEN 1600 7
WARD 1250 10
JONES 2975 4
MARTIN 1250 10
BLAKE 2850 5
CLARK 2450 6
SCOTT 3000 2
KING 5000 1
TURNER 1500 8
ADAMS 1100 12
JAMES 950 13
FORD 3000 2
MILLER 1300 9
*/
RANK()함수를 사용하지 않고 서브상관쿼리를 활용해 EMP 테이블을 대상으로 사원명, 급여, 부서번호, 부서내급여등수, 전체급여등수 항목을 조회한다.
SELECT ENAME "사원명", SAL "급여", DEPTNO "부서번호"
, (SELECT COUNT(*) + 1
FROM EMP
WHERE SAL > E.SAL) "전체급여등수"
, (SELECT COUNT(*) + 1
FROM EMP
WHERE SAL > E.SAL
AND DEPTNO = E.DEPTNO) "부서내급여등수"
FROM EMP E;
--==>>
/*
SMITH 800 20 14 5
ALLEN 1600 30 7 2
WARD 1250 30 10 4
JONES 2975 20 4 3
MARTIN 1250 30 10 4
BLAKE 2850 30 5 1
CLARK 2450 10 6 2
SCOTT 3000 20 2 1
KING 5000 10 1 1
TURNER 1500 30 8 3
ADAMS 1100 20 12 4
JAMES 950 30 13 6
FORD 3000 20 2 1
MILLER 1300 10 9 3
*/
'SQL > Oracle' 카테고리의 다른 글
| 프로젝트 DB 설계에 관하여 (0) | 2023.04.03 |
|---|---|
| 30. ROW_NUMBER, 시퀀스(SEQUENCE) (0) | 2022.03.29 |
| 28. HAVING (0) | 2022.03.12 |
| 27. CUBE (0) | 2022.03.12 |
| 26. ROLLUP, GROUPING (0) | 2022.03.12 |
HAVING
EMP 테이블에서 부서번호가 20, 30 인 부서를 대상으로 부서의 총 급여가 10000 보다 적을 경우만 부서별 총 급여를 조회한다.
SELECT DEPTNO, SUM(SAL)
FROM EMP
WHERE DEPTNO IN (20, 30)
AND SUM(SAL) < 10000
GROUP BY DEPTNO;
--==>> 에러 발생
-- ORA-00934: group function is not allowed here
-- (GROUP 함수를 일반 WHERE에서 쓸 수 없어서 생기는 오류)
-- 1
SELECT DEPTNO, SUM(SAL)
FROM EMP
WHERE DEPTNO IN (20, 30)
GROUP BY DEPTNO
HAVING SUM(SAL) < 10000;
--==>> 30 9400
-- 2
SELECT DEPTNO, SUM(SAL)
FROM EMP
GROUP BY DEPTNO
HAVING SUM(SAL) < 100000
AND DEPTNO IN (20, 30);
--==>> 30 9400
같은 결과이긴 하지만 FROM과 WHERE로 1차적 메모리를 올리고 그 이후에 추가적으로 계산하는데 이 논리로 보면 오라클에게는 1번을 조금 더 원할하게 처리
이러한 작은 차이가 퍼포먼스로 이어진다.

부족하거나 잘못된 내용이 있을 경우 댓글 달아주시면 감사하겠습니다.
이 글에 부족한 부분이 존재할 경우 추후에 수정될 수 있습니다.
'SQL > Oracle' 카테고리의 다른 글
| 30. ROW_NUMBER, 시퀀스(SEQUENCE) (0) | 2022.03.29 |
|---|---|
| 29. 중첩 그룹함수 / 분석함수 (0) | 2022.03.12 |
| 27. CUBE (0) | 2022.03.12 |
| 26. ROLLUP, GROUPING (0) | 2022.03.12 |
| 25. 그룹 함수 (0) | 2022.03.12 |
CUBE()
ROLLUP()보다 더 디테일한 결과 반환
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY CUBE(DEPTNO, JOB)
ORDER BY 1, 2;
--==>>
/*
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 (null) 8750
20 ANALYST 6000
20 CLERK 1900
20 MANAGER 2975
20 (null) 10875
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
30 (null) 9400
(null) ANALYST 6000 -- 모든 부서 ANALYST 직종의 급여합
(null) CLERK 4150 -- 모든 부서 CLERK 직종의 급여합
(null) MANAGER 8275 -- 모든 부서 MANAGER 직종의 급여합
(null) PRESIDENT 5000 -- 모든 부서 PRESIDENT 직종의 급여합
(null) SALESMAN 5600 -- 모든 부서 SALESMANE 직종의 급여합
(null) (null) 29025
*/
※ ROLLUP() 과 CUBE() 는 그룹을 묶어주는 방식이 다르다(차이)
EX.
ROLLUP(A, B, C)
→ (A, B, C) / (A, B) / (A) / ()
CUBE(A, B, C)
→ (A, B, C) / (A, B) / (A, C) / (B, C) / (A) / (B) / (C) / ()
ROLLUP()은 묶음 방식이 다소 모자라고 CUBE()는 묶음 방식이 다소 지나치기 때문에 조회하고자 하는 그룹만 『GROUPING SETS』를 이용하여 묶어주는 방식의 쿼리 형태를 더 많이 사용한다.
-- ROLLUP 사용
SELECT CASE GROUPING(DEPTNO) WHEN 0 THEN NVL(TO_CHAR(DEPTNO), '인턴')
ELSE '전체부서'
END "부서번호"
, CASE GROUPING(JOB) WHEN 0 THEN JOB
ELSE '전체직종'
END "직종"
, SUM(SAL) "급여합"
FROM TBL_EMP
GROUP BY ROLLUP(DEPTNO, JOB)
ORDER BY 1, 2;
--==>>
/*
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 전체직종 8750
20 ANALYST 6000
20 CLERK 1900
20 MANAGER 2975
20 전체직종 10875
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
30 전체직종 9400
인턴 CLERK 3500
인턴 SALESMAN 5200
인턴 전체직종 8700
전체부서 전체직종 37725
*/
-- CUBE 사용
SELECT CASE GROUPING(DEPTNO) WHEN 0 THEN NVL(TO_CHAR(DEPTNO), '인턴')
ELSE '전체부서'
END "부서번호"
, CASE GROUPING(JOB) WHEN 0 THEN JOB
ELSE '전체직종'
END "직종"
, SUM(SAL) "급여합"
FROM TBL_EMP
GROUP BY CUBE(DEPTNO, JOB)
ORDER BY 1, 2;
--==>>
/*
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 전체직종 8750
20 ANALYST 6000
20 CLERK 1900
20 MANAGER 2975
20 전체직종 10875
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
30 전체직종 9400
인턴 CLERK 3500
인턴 SALESMAN 5200
인턴 전체직종 8700
전체부서 ANALYST 6000
전체부서 CLERK 7650
전체부서 MANAGER 8275
전체부서 PRESIDENT 5000
전체부서 SALESMAN 10800
전체부서 전체직종 37725
*/
GROUPING SETS
-- CUBE()를 사용한 결과와 같은 조회 결과
SELECT CASE GROUPING(DEPTNO) WHEN 0 THEN NVL(TO_CHAR(DEPTNO), '인턴')
ELSE '전체부서'
END "부서번호"
, CASE GROUPING(DEPTNO) WHEN 0 THEN JOB
ELSE '전체직종'
END "직종"
, SUM(SAL) "급여합"
FROM TBL_EMP
GROUP BY GROUPING SETS((DEPTNO, JOB), (DEPTNO), (JOB), ())
--==>>
/*
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 전체직종 8750
20 ANALYST 6000
20 CLERK 1900
20 MANAGER 2975
20 전체직종 10875
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
30 전체직종 9400
인턴 CLERK 3500
인턴 SALESMAN 5200
인턴 전체직종 8700
전체부서 ANALYST 6000
전체부서 CLERK 7650
전체부서 MANAGER 8275
전체부서 PRESIDENT 5000
전체부서 SALESMAN 10800
전체부서 전체직종 37725
*/
-- ROLLUP()을 사용한 결과와 같은 조회 결과
SELECT CASE GROUPING(DEPTNO) WHEN 0 THEN NVL(TO_CHAR(DEPTNO), '인턴')
ELSE '전체부서'
END "부서번호"
, CASE GROUPING(JOB) WHEN 0 THEN JOB
ELSE '전체직종'
END "직종"
, SUM(SAL) "급여합"
FROM TBL_EMP
GROUP BY GROUPING SETS((DEPTNO, JOB), (DEPTNO), ())
ORDER BY 1, 2;
--==>>
/*
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 전체직종 8750
20 ANALYST 6000
20 CLERK 1900
20 MANAGER 2975
20 전체직종 10875
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
30 전체직종 9400
인턴 CLERK 3500
인턴 SALESMAN 5200
인턴 전체직종 8700
전체부서 전체직종 37725
*/

부족하거나 잘못된 내용이 있을 경우 댓글 달아주시면 감사하겠습니다.
이 글에 부족한 부분이 존재할 경우 추후에 수정될 수 있습니다.
'SQL > Oracle' 카테고리의 다른 글
| 29. 중첩 그룹함수 / 분석함수 (0) | 2022.03.12 |
|---|---|
| 28. HAVING (0) | 2022.03.12 |
| 26. ROLLUP, GROUPING (0) | 2022.03.12 |
| 25. 그룹 함수 (0) | 2022.03.12 |
| 24. RANK() (0) | 2022.03.12 |
ROLLUP
총합
SELECT DEPTNO "부서번호", SUM(SAL) "급여합"
FROM TBL_EMP
GROUP BY ROLLUP(DEPTNO);
--==>>
/*
10 8750
20 10875
30 9400
(null) 8700 -- 부서번호를 갖지 못한 직원들의 급여합
(null) 37725 -- 모든부서 직원들의 급여합
*/
-- TBL_EMP의 경우 DEPTNO이 NULL인 경우가 포함되어 있다.
SELECT NVL2(DEPTNO, TO_CHAR(DEPTNO), '모든부서') "부서번호", SUM(SAL) "급여합"
FROM EMP
GROUP BY ROLLUP(DEPTNO);
--==>>
/*
10 8750
20 10875
30 9400
모든부서 29025
*/
-- EMP의 경우 DEPTNO가 NULL인 값이 없어 이렇게 처리 가능
-- 반면 DEPTNO에 NULL이 존재하는 TBL_EMP의 경우는 NVL을 사용해도 아래와 같은 문제 발생
SELECT NVL(TO_CHAR(DEPTNO), '모든부서') "부서번호", SUM(SAL) "급여합"
FROM TBL_EMP
GROUP BY ROLLUP(DEPTNO);
--==>>
/*
10 8750
20 10875
30 9400
모든부서 8700
모든부서 37725
*/
이러한 문제는 GROUPING으로 해결 할 수 있다.
GROUPING()
총합으로 집계된 데이터는 1을 반환하고 아닐 경우 0을 반환
SELECT GROUPING(DEPTNO) "GROUPING", DEPTNO "부서번호", SUM(SAL) "급여합"
FROM EMP
GROUP BY ROLLUP(DEPTNO);
--==>>
/*
0 10 8750
0 20 10875
0 30 9400
1 29025
*/
-- 위에서 TBL_EMP에서 NULL로 인한 문제의 경우 아래로 해결 가능
SELECT CASE GROUPING(DEPTNO) WHEN 0 THEN NVL(TO_CHAR(DEPTNO), '인턴')
ELSE '모든부서'
END "부서번호"
, SUM(SAL) "급여합"
FROM TBL_EMP
GROUP BY ROLLUP(DEPTNO);
--==>>
/*
부서번호 급여합
10 8750
20 10875
30 9400
인턴 8700
모든부서 37725
*/
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY ROLLUP(DEPTNO, JOB)
ORDER BY 1, 2;
--==>>
/*
10 CLERK 1300 -- 10번 부서 CLERK 직종의 급여합
10 MANAGER 2450 -- 10번 부서 MANAGER 직종의 급여합
10 PRESIDENT 5000 -- 10번 부서 PRESIDENT 직종의 급여합
10 (null) 8750 -- 10번 부서 모든 직종의 급여합 -- CHECK~!!!
20 ANALYST 6000 -- 20번 부서 ANALYST 직종의 급여합
20 CLERK 1900 -- 20번 부서 CLERK 직종의 급여합
20 MANAGER 2975 :
20 (null) 10875 -- 20번 부서 모든 직종의 급여합 -- CHECK!!
30 CLERK 950
30 MANAGER 2850 :
30 SALESMAN 5600
30 (null) 9400 -- 30번 부서 모든 직종의 급여합 -- CHECK!!
(null) (null) 29025 -- 모든 부서 모든 직종의 급여합 -- CHECK!!
*/

부족하거나 잘못된 내용이 있을 경우 댓글 달아주시면 감사하겠습니다.
이 글에 부족한 부분이 존재할 경우 추후에 수정될 수 있습니다.
'SQL > Oracle' 카테고리의 다른 글
| 28. HAVING (0) | 2022.03.12 |
|---|---|
| 27. CUBE (0) | 2022.03.12 |
| 25. 그룹 함수 (0) | 2022.03.12 |
| 24. RANK() (0) | 2022.03.12 |
| 23. VIEW (0) | 2022.03.12 |